
Observability in the Age of Gen AI
What is Observability?
A simple way of describing observability is how well you can understand the system and it’s internal state from the outputs it generates.
Expanded to IT, software, and cloud computing, observability is how engineers can understand the current state of a system from the data it generates. To fully understand, you’ve got to proactively collect the right data, then visualise it, and apply intelligence.
Observability provides a proactive approach to troubleshooting and optimising software systems effectively. It offers a real-time and interconnected perspective on all operational data within a software system, enabling on-the-fly inquiries about applications and infrastructure.
In the modern era of complex systems developed by distributed teams, observability is essential. Observability goes beyond traditional monitoring by allowing engineers to understand not only what is wrong but also why something broke down.
The Market
The observability market is huge. To give you an idea - “For every $1 you spend on public cloud, you’re likely spending $0.25–$0.35 on observability” - The observability and monitoring market was valued at $41B at the end of 2022 and is poised to grow to $62B by the end of 2026.
Organisations are willing to pay for the right tools which is highlighted by DataDog’s annual posted revenues to the tune of $2B in FY23. Coinbase was billed $65M in Datadog expenses alone in 2021, highlighting how these costs can be much larger than one can imagine.
.png)
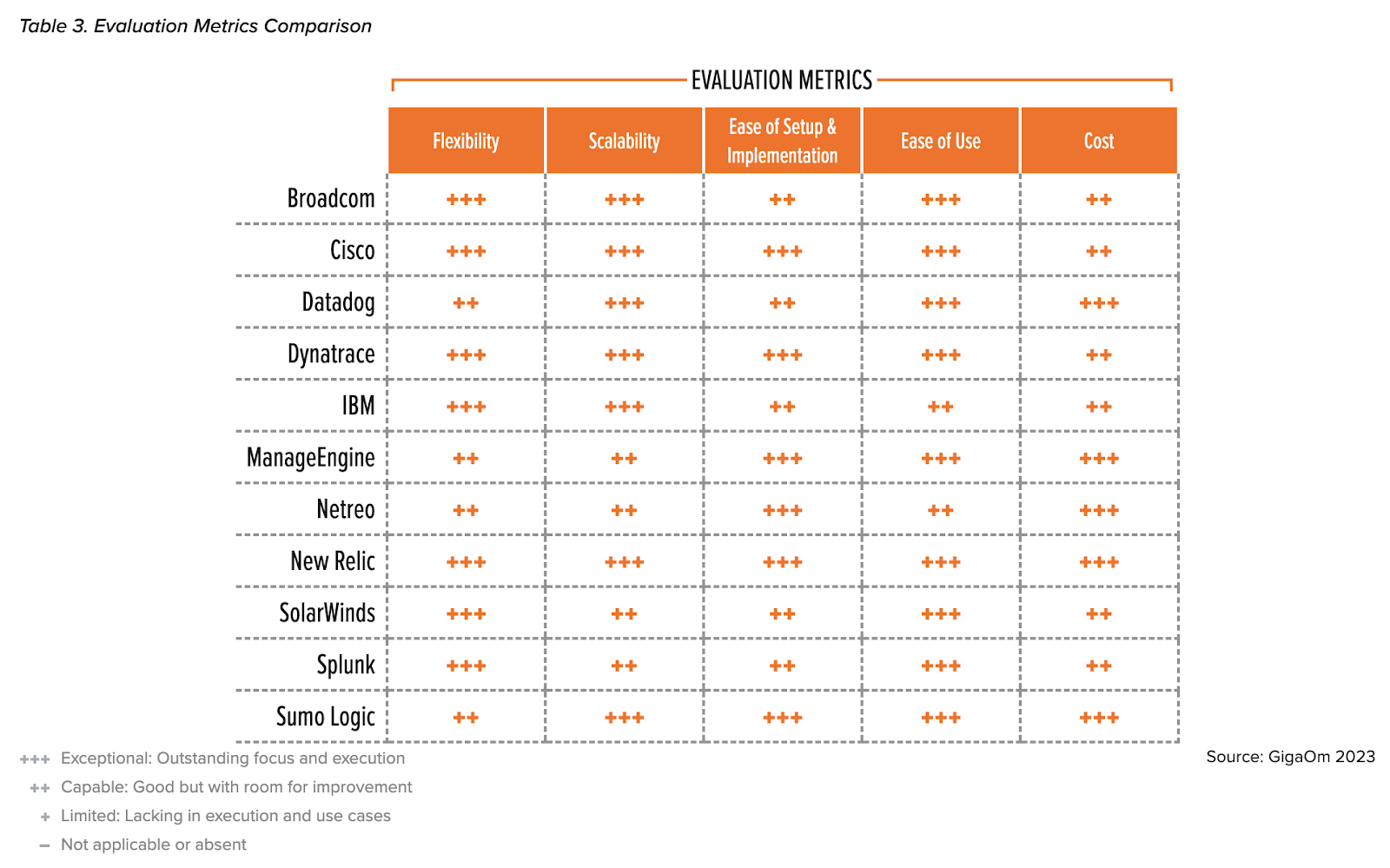
In essence, this is a mature space with players like Splunk, Datadog, Grafana, New Relic and others taking up significant wallet share of software enterprises. These companies are innovating daily and the table below helps us understand their strengths/ focus areas:
How is Generative AI Impacting the Space?
Traditional ML algorithms, such as decision trees, random forests, and clustering algorithms, were and are used in AIOps for tasks such as anomaly detection, root cause analysis, and predictive analytics. Traditional ML techniques played a crucial role in AIOps by providing the foundational algorithms and methodologies for automating IT operations tasks. However, the advent of LLMs has further advanced the capabilities of AIOps by enabling more sophisticated natural language processing and understanding, which can be particularly useful for analyzing unstructured data such as logs and alerts. Foundational models are able to effectively “apply intelligence” by “inquiring” the system about observability data (think MELT - metrics, events, logs and traces) to get a faster understanding of the “why”. Due to the readily available data and need for such solutions in the market, this is one the first areas where generative AI is witnessing immediate applications. In addition to traditional machine learning approaches that have their own salient points, LLMs create value in a number of new ways.
Some of the key differences between traditional ML models and LLMs are as follows:
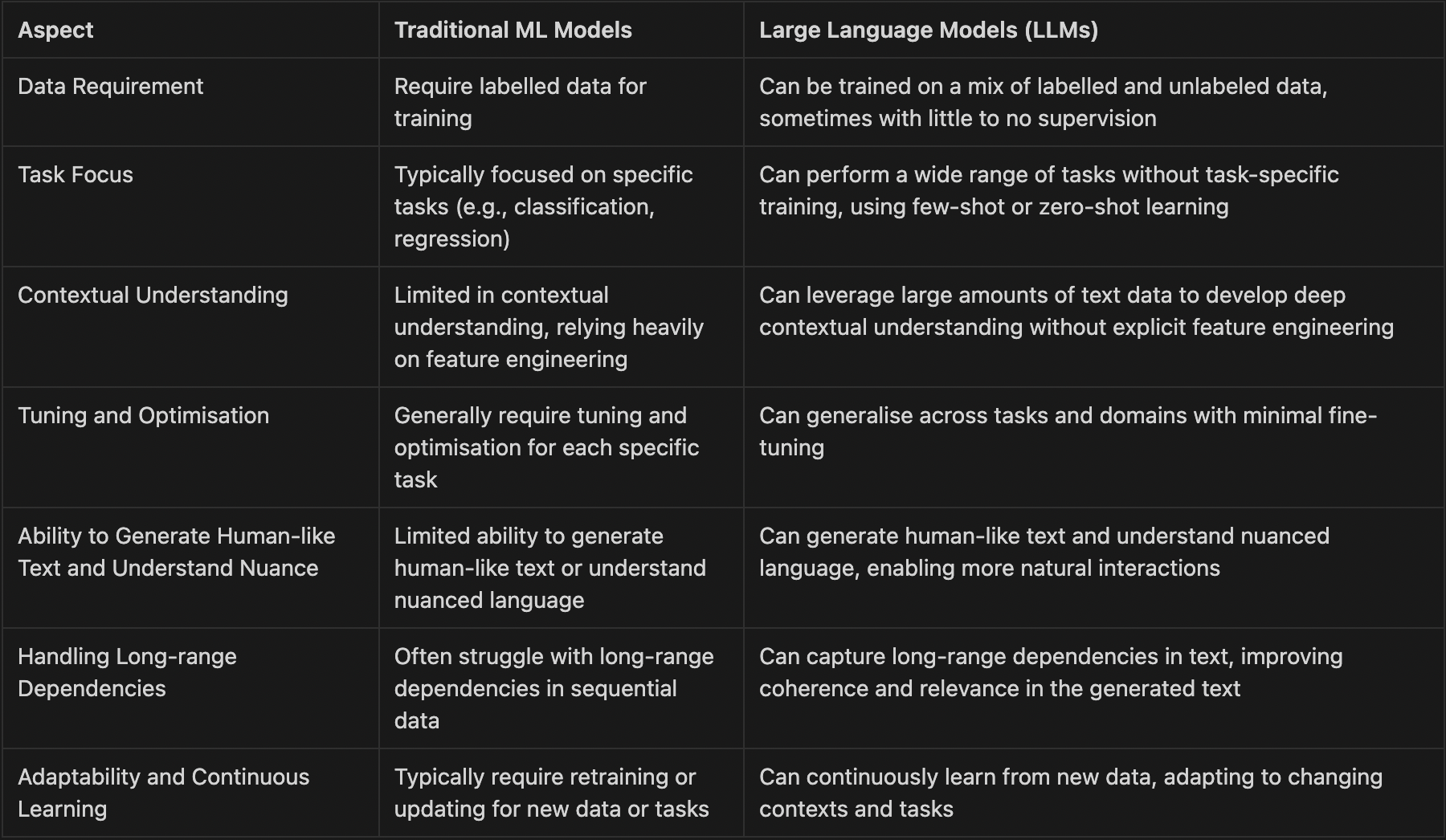
These capabilities are very useful for the observability problem statement since in essence the field revolves around understanding time-series system data to understanding more about the current and possible future states of the system.
Challenges in Observability
The most surprising part of the earning’s call by Datadog was this - “Management projects its core observability and monitoring market will grow at a 10.89% compound annual growth rate (CAGR) from $41 billion at the end of 2022 to $62 billion at the end of 2026. Thus far, Datadog has only captured a 4.36% share of this market, so the company has a long runway for growth.”
Despite a myriad of tools, the following challenges still exist which were independently confirmed through our discussions with various users and reports all across:
1. Tool Sprawl: Separate storage tools are typically used for each telemetry data type: logs, metrics, and traces, creating additional cost and complexity to manage.
.png)
.png)
2. Increasing TCO: Observability tools are notoriously known for large bills highlighted in the graph below. This is primarily due to high tool sprawl and index storage costs across.
.png)
Additionally, IT budgets are being rationalised:
.png)
3. Shortage of Talent: Resolving incidents requires a large surface area of unique skills. These skills are usually only developed after years of trial and error, so solving complex production problems requires senior SREs which are hard to hire.
.png)
Additionally, layoffs affect the MTTR for incidents as well (fuelling into the SRE problem):
.png)
The biggest shift during current times has been the advent of large language models to extract precise information faster and better. Basis this, we have seen multiple players starting up here.
Areas of Opportunity in Observability
- A leapfrog opportunity for new entrants - LLMs have unlocked a massive opportunity for new entrants to re-imagine the way observability tools are used and built. Larger, well distributed tools have strong distribution but come with pre-built datastack which is inherently unsuitable for AI-based copiloting. For example, the co-pilots being marketed and distributed by Datadog or Splunk use LLMs to understand user-intent and SQL query generation alone. Although useful, this does not use the full potential of the paradigm which can be utilised to reimagine the entire storage stack for MELT metrics since LLMs thrive in unstructured data. Tool sprawl fatigue is another promising area which can be reduced significantly using LLMs. Using larger models as an insight pane over existing tools for summarisation and prioritisation is promising. Larger players will not do it themselves owing to their long-standing one-tool-for-everything mission.
- Operational agents - LLMs have strong reasoning abilities and retain context reasonably well about previous conversation which is bound to be better with time. This enables automation of preliminary SRE activities of pulling up relevant data and structuring probable reasons in using current models itself. Complete automation of this although not-on-the-cards currently, is clearly the future. On the flip-side, the overall opportunity for buyers is to build a leaner organisation without sacrificing performance using these tools and hence is a win-win.
- Workflow improvements - Most organisations today use multiple observability tools owing to differentiation in MELT databases. Owing to the complex nature of architecture and tooling, SRE churn leads to major knowledge gaps inside businesses. With the advent of co-pilots, this gap can be plugged by revamping the way tools are interacted with in this space. Initial knowledge ramp-up required can be reduced significantly by leveraging contextual knowledge retention. There are also numerous opportunities to reimagine the user interface itself given these new tools. Designing great UX makes a massive difference to adoption outcomes & we did a deep-dive on this topic here.
Building Observability Tools with LLMs: Key Considerations
Despite the crowded landscape there’s more to be done with the paradigm shift in the making with LLMs. We think that the following factors should be considered as guiding markers for starting up here at the outset:
- Entry into the workflow - Most businesses which lie in the ICP of observability tools are already using some tools. We imagine that a good starting point here can solve a single problem really well whilst co-existing with the existing stack. The key here is to land and expand by adding immediate value for the user from day-1. Although larger players offer a full suite of offerings, often point solution improvements cater to niches in the market; helping products enter the target ICP’s work-stream. For example, prevalent issues like alert fatigue can be solved using contextual prioritisation and summarisation abilities of the models.
- Product expansion roadmap - Most businesses we see here want to build out the entire observability layer over time. In our understanding, product expansion for land and expand needs to be very well thought out with clear pull from early users for these features. Looping in an SRE persona/ team as a design partner and building with them can be a good way to go about this.
- Pricing - Rise of AI in software is making usage based pricing as the de-facto owing to variable inferencing costs. Pricing in observability has been one of the biggest worries for users. This cost could spike even due to frequent LLM calls for minor tasks. Startups will have to justify the addition spend & the variability in costs by clearly communicating how they drive meaningful value.
- GTM - Equal emphasis on the GTM roadmap (if not more as compared to the product) which is validated by early efforts towards the same is important in this crowded segment. We think innovation here is critical to solve for early adoption (e.g. partnering with the right channel partners in target geographies, going vertical into certain niche categories with pillar customers etc.).
In summary, this is a large addressable spend and the flexibility of new tools can lead to massive value unlock by simplifying the path to outcomes. We’re ready for some big changes in this space and excited to see what startups build.













